Note préliminaire : étant directement impliqué dans le Hackaton Marine Nationale qui vient de s’achever, je prie mes lecteurs de m’excuser pour le rythme ralenti de publication de ces derniers jours : mon travail m’occupant la journée, et le Hackaton mes nuits (en tant qu’officier de réserve), il m’était difficile de poursuivre intensément toutes mes autres activités.
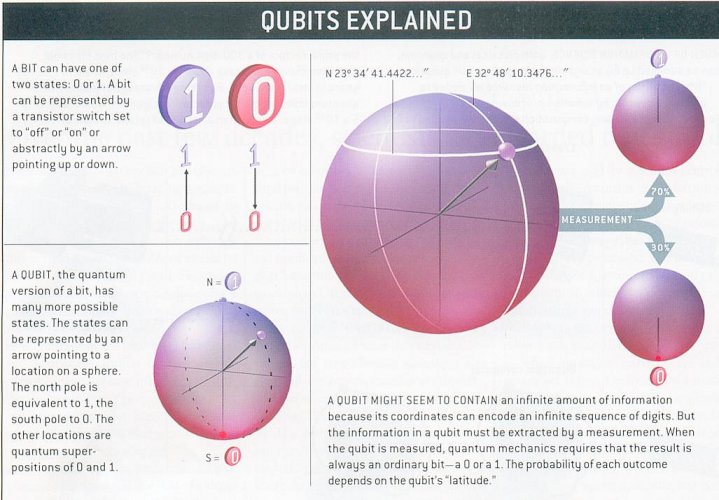
Nous avions déjà parlé de l’ordinateur quantique et de ses implications pour le monde de la défense (voir par exemple cet article). La société IBM annonce d’ailleurs avoir développé et déployé deux nouveaux ordinateurs quantiques à 16 et 17 qbits, au sein de son centre de recherche Q Lab (ci-dessous), un progrès significatif dans la mesure où leur prédécesseur ne comportait que 5 qbits.

L’ordinateur quantique est l’une des révolutions portées par un nouveau domaine, l’informatique moléculaire (molecular informatics en anglais). Comme son nom l’indique, il s’agit de stocker et de traiter l’information en se fondant sur les propriétés des molécules, au lieu d’utiliser le silicium. Il s’agit d’un nouveau champ de recherche, mêlant informatique, chimie, mathématiques et ingénierie.
L’idée en soi n’est pas nouvelle ; elle consiste à utiliser les propriétés des molécules : charge, structure, volume, polarité… pour concevoir de nouveaux modèles de calcul et de stockage, allant bien au-delà des capacités des machines traditionnelles. Plusieurs expérimentations sont en cours depuis longtemps. Ainsi, on connaît les puces « à ADN » (à ne pas confondre avec les DNA Chips, des dispositifs de biologie moléculaire), qui ont vu le jour en 1994. Inventé par un chercheur, Leonard Adleman, le principe repose sur les propriétés de la molécule d’ADN. Il s’agit de coder un problème non avec des 0 et des 1 mais en utilisant les quatre constituant fondamentaux (bases) de l’ADN : la Cytosine, la Guanine, la Thymine et l’Adénine (oui, je suis biologiste au départ). En gros, on code un problème en utilisant des séquences A,T,G,C dans une molécule d’ADN. Juste pour rappeler : les bases A se lient aux T, les G se lient aux C ; cette propriété permet d’hybrider deux molécules d’ADN, ou d’en lier certaines séquences.

En utilisant ce principe, on peut trouver une solution à un problème de recherche combinatoire (en utilisant toutes les combinaisons de molécules, et leur hybridation, ce qui réalise, en quelque sorte, un ordinateur parallèle), mais on peut également créer des « portes logiques » (des « aiguillages logiques », à la base de l’informatique, comme ET, OU, XOR…) en se reposant sur les liaisons entre molécules d’ADN. Je ne rentre pas dans les détails, voici par exemple un article expliquant le principe, dans des termes assez simples.
L’intérêt, c’est de pouvoir, dans un volume très réduit, disposer de millions de milliards de molécules, constituant ainsi un ordinateur parallèle extrêmement compact. Cela permet donc de pouvoir, en théorie, traiter des problèmes complexes : optimisation combinatoire, apprentissage, analyse de signal ou d’image, etc… Bien évidemment, si cela fonctionnait aujourd’hui, cela se saurait. Les limitations sont dues à la complexité – et à la lenteur – de cette technologie. C’est pourquoi ce champ de recherche est resté « en friche » depuis deux décennies.

Ce qui explique l’explosion du domaine aujourd’hui, c’est que le volume et la complexité des données devant être traitées et stockées (« Big Data ») mène les architectures informatiques classiques à leurs limites. Il devient donc urgent de trouver des moyens efficaces de traiter l’information, mais aussi de la stocker. L’informatique moléculaire répond à ces deux impératifs.
Reprenons notre exemple de l’ordinateur à ADN. Des chercheurs de l’université de Manchester ont montré qu’il était extrêmement intéressant dans le domaine du stockage de l’information, grâce à sa propriété d’auto-réplication. Là aussi, simplifions : un gramme d’ADN peut stocker l’équivalent d’un Téraoctet d’informations. Mais surtout, l’ADN peut s’auto-répliquer. On a donc l’équivalent d’un disque dur capable d’augmenter sa capacité en cas de besoin. Cette propriété d’auto-réplication peut d’ailleurs être également utilisée en termes de calcul, pour explorer deux voies de recherche à la fois.
Imaginez donc les implications : des ordinateurs parallèles et des bases de données gigantesques tenant dans un volume extraordinairement compact. Bon, le souci c’est notamment le prix : l’ADN doit être synthétisé et cela coûte cher. On estime que le stockage d’1 MB en utilisant l’ADN coûterait aujourd’hui entre 10000 et 15000 EUR.

Il y a donc de nombreux défis inhérents à la technique de l’informatique moléculaire. Mais le domaine est en plein développement, qu’il s’agisse d’élaborer des mélanges moléculaires complexes pour le calcul, de développer des portes logiques biomoléculaires, ou de synthétiser de nouveaux polymères (la liste n’est pas exhaustive). Par exemple, les molécules polyoxométalates (POM) – ci-dessus- peuvent agir comme des nœuds de stockage permettant de créer des mémoires Flash à l’échelle nanométrique.
Pour développer le domaine, il faut, en particulier, dépasser les limitations de l’ordinateur à ADN, qui nécessite d’utiliser un ordinateur traditionnel pour récupérer et traiter l’information, ralentissant donc singulièrement le processus, et diminuant l’intérêt du système.

C’est pourquoi la DARPA vient de lancer un appel à propositions, afin d’identifier des programmes et pistes de recherche permettant de lever ces limitations. Car l’implication pour le monde de la défense est considérable, dans des domaines comme le traitement d’images pour la reconnaissance, la guerre électronique, le renseignement SIGINT, le traitement des données sur le théâtre d’opérations, etc.
La première phase (18 mois) du programme de la DARPA consistera à élaborer des stratégies de codage de l’information et de calcul en informatique moléculaire. La seconde phase (de 18 mois également) consistera à intégrer et démontrer la pertinence de ces stratégies en codant et en traitant de gros volumes de données. Le défi ? Démontrer la capacité de traiter et stocker 1 GB de données en utilisant un système biomoléculaire d’une densité de 1018 octets par mm3 !
Pour les lecteurs intéressés, l’appel à propositions de la DARPA peut être trouvé ici. Vous avez jusqu’au 12 juin, donc bon courage 🙂